Anthropic 엔지니어가 직접 공개한 Fable 5 루프 설계 기법 — 자가 수정 루프(self-correction loop)와 메모리(memory) — 를 데이터 분석가의 언어로 풀고, 타이타닉 데이터셋 하나로 결측치 점검 → EDA → 모델 개선까지 루프를 설계하는 실전 방법을 정리했습니다.
Fable 5 루프 설계, 프롬프트만 열심히 쓰는데 결과가 제자리인 이유가 궁금하지 않으세요?
루프 설계(loop engineering)는 AI에게 ‘A 해줘, 그다음 B 해줘’라고 매번 지시하는 대신, AI가 스스로 ‘실행 → 점검 → 수정’을 반복하도록 작업 구조와 종료조건을 짜주는 방식입니다. 데이터 분석을 시킬 때 결측치 처리·EDA·재학습을 한 단계씩 일일이 떠먹여 본 적 있다면, 바로 그 비효율을 없애는 접근이에요.
실제로 Anthropic의 Lance Martin이 공개한 사례에서는 같은 과제에서 Fable 5가 Opus 4.7보다 학습 파이프라인을 약 6배 더 개선했는데, 그 차이를 만든 건 모델 성능이 아니라 ‘루프 설계 방식’이었습니다. 이 개념을 데이터 분석가 입장에서 타이타닉 데이터셋에 어떻게 적용하는지 단계별로 풀어봤어요. 😮
📌 목차
- Fable 5 루프 설계란? 신입 분석가에게 일 시키는 법과 같습니다
- Parameter Golf: 6배 차이를 만든 건 모델이 아니라 루프
- 타이타닉 루프 ①: 데이터 로드·결측치 점검 루프
- 타이타닉 루프 ②: EDA 교차분석을 반복시키는 법
- 타이타닉 루프 ③: 모델 개선 hillclimb 루프와 종료조건
- Memory: 세션을 넘어 똑똑해지는 outer loop
- 이런 분들께 적극 추천합니다
- 자주 묻는 질문 (FAQ)
1. Fable 5 루프 설계란? 신입 분석가에게 일 시키는 법과 같습니다
비유부터 시작할게요. 유능한 신입 분석가에게 일을 맡길 때, 옆에 붙어서 “이제 groupby 하세요”라고 한 줄씩 지시하진 않잖아요. 대신 목표와 합격 기준을 주죠. “생존율에 영향을 주는 변수 3개를 찾고, 근거 수치를 표로 정리해서 가져오세요”처럼요. Fable 5 루프 설계가 정확히 이 방식이에요.
① Self-correction Loop — 실행, 피드백, 수정의 반복
원문에서 제시한 레시피는 단순합니다. 잘 설계된 goal과 rubric이 환경에 피드백을 주입하면, Claude는 “실행 → 피드백 수집 → 자가 수정”을 목표가 충족될 때까지 반복해요. Anthropic 내부에서는 “내 일은 루프를 작성하는 것”이라는 말까지 나왔다고 하고요. Claude Code의 /goal, Claude Managed Agent의 Outcomes가 바로 이 레시피를 구현하는 기본 도구(primitive)입니다.
💡 실제 활용 시나리오 예시:
매주 반복되는 매출 데이터 정합성 점검을 “컬럼별 결측·이상치 리포트가 모두 PASS일 때까지 수정 반복”이라는 rubric으로 위임한 분석팀은, 사람이 개입하던 점검 시간을 회당 2시간에서 10분 검토로 줄였습니다.
② Verifier Sub-agent — 채점은 반드시 남에게 맡겨라
여기서 핵심이 있어요. 원문에 따르면 모델은 자기 출력에 대한 self-critique에 약점이 있습니다. 자기가 쓴 코드를 자기가 채점하면 후하게 주는 거죠. 그래서 독립된 컨텍스트 윈도우에서 채점하는 verifier sub-agent가 self-critique보다 우수하다는 게 실험으로 확인됐어요. CMA의 Outcomes는 이 grader sub-agent를 자동으로 생성해줍니다.
💡 실제 활용 시나리오 예시:
분석 보고서 자동화 파이프라인에서 “작성 에이전트”와 “수치 검증 에이전트”를 분리하자, 집계 오류가 검증 단계에서 걸러지는 비율이 눈에 띄게 올라갔다는 사례가 실무자들 사이에서도 자주 언급되더라고요.
2. Parameter Golf: 6배 차이를 만든 건 모델이 아니라 루프
Parameter Golf는 16MB 안에 들어가는 최고 성능 모델을 8xH100 GPU에서 10분 이내에 학습시키는 오픈소스 ML 엔지니어링 챌린지예요. 단일 train_gpt.py 파일을 편집하고, 학습을 돌리고, 로그를 폴링하고, 점수를 확인하고, 다음 실험을 결정하는 능력을 시험하죠. 데이터 사이언티스트가 매일 하는 “실험 사이클” 그 자체입니다.
1) 결과 — 구조적 베팅 vs 스칼라 반복
9개의 체크 가능한 기준(baseline 실행, 실험 20회 수행 등)을 담은 rubric을 주고 최대 8시간 실행한 결과, Fable 5가 Opus 4.7 대비 약 6배 더 파이프라인을 개선했어요. 흥미로운 건 개선의 방식이었습니다.
| 구분 | Fable 5 | Opus 4.7 |
|---|---|---|
| 실험 스타일 | 아키텍처를 바꾸는 큰 구조적 변경에 베팅 | 상수 조정(스칼라) 중심의 동일 템플릿 반복 |
| 실패 대응 | quantization regression을 뚫고 최대 성과 달성 | 첫 실험의 작은 성과 후 “조정·측정·유지” 반복 |
| 최종 개선폭 | 약 6배 우위 | 기준선 수준 |
💡 실제 활용 시나리오 예시:
하이퍼파라미터만 만지며 0.5%p씩 올리던 추천 모델 프로젝트에서, 에이전트에게 “피처 구조 변경 실험을 최소 5회 포함”이라는 rubric을 추가하자 임베딩 구조 교체라는 큰 개선안이 나온 경우처럼, rubric이 탐색 범위를 결정합니다.
3. 타이타닉 루프 ①: 데이터 로드·결측치 점검 루프
| 컬럼 | 결측 수 | 결측률 | 루프의 판단 |
|---|---|---|---|
| deck | 688명 | 77.2% | 과반 결측 → 컬럼 제거 후보 |
| age | 177명 | 19.9% | 중앙값·그룹별 대치 검토 |
| embarked | 2명 | 0.2% | 최빈값으로 간단 대치 |
💡 실제 데이터로 확인:
실측 타이타닉 891명에서 deck는 77.2%가 비어 있습니다. 사람이면 놓치기 쉽지만, 결측률 임계치(예: 40% 초과 시 제거)를 종료조건으로 걸어두면 루프가 스스로 “deck는 버리고 age는 대치한다”는 결정을 반복 적용합니다.
이제 이걸 우리 일에 가져와볼게요. 모두가 아는 타이타닉 데이터셋으로 시작합니다. 보통은 “Age 결측치 채워줘”라고 지시하지만, 루프 설계에서는 합격 기준이 담긴 목표를 줍니다.
1) 프롬프트 예시 — 종료조건을 명시하기
목표: titanic.csv를 분석 가능한 상태로 만들 것
Rubric (모두 충족할 때까지 스스로 수정·반복):
1. 전 컬럼 결측치 0% (처리 방법과 근거를 기록할 것)
2. Age는 단순 평균 대치 금지 — Pclass·Sex 그룹별 중앙값 사용
3. Cabin처럼 결측 77% 이상 컬럼은 삭제 대신 '유무' 파생변수 검토
4. 처리 전후 분포 비교 리포트 생성 (skew 변화 명시)
검증: 별도 verifier 단계에서 df.isnull().sum() 결과가
전부 0인지 확인 후에만 작업 종료차이가 보이시나요? “무엇을 하라”가 아니라 “무엇이 충족되면 끝인가”를 정의했어요. Fable 5는 이 rubric을 피드백 삼아 결측치 처리 → 검증 → 미달 시 재수정을 스스로 반복합니다. 이게 생각보다 중요한 이유가 있어요. 종료조건이 없으면 모델은 “대충 한 번 처리하고 끝”내거든요.
💡 실제 활용 시나리오 예시:
고객 데이터 웨어하우스에 매일 들어오는 신규 테이블 검수를 이런 rubric 루프로 돌리면, “결측·타입 불일치·중복 키 3종 체크 전부 PASS”가 될 때까지 에이전트가 알아서 정제하고, 분석가는 최종 리포트만 확인하면 됩니다.
4. 타이타닉 루프 ②: EDA 교차분석을 반복시키는 법
실제 타이타닉 데이터(891명)로 돌려보면 숫자가 이렇게 나옵니다. 전체 생존율은 38.4%인데, 성별로 쪼개면 여성 74.2% vs 남성 18.9%로 갈립니다. 여기에 객실 등급을 교차하면 격차가 더 선명해집니다.
| 생존율(%) | 1등석 | 2등석 | 3등석 |
|---|---|---|---|
| 여성 | 96.8 | 92.1 | 50.0 |
| 남성 | 36.9 | 15.7 | 13.5 |
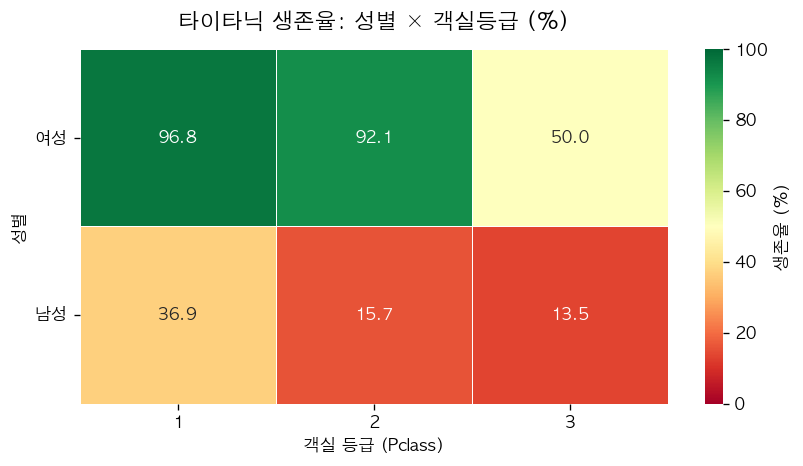
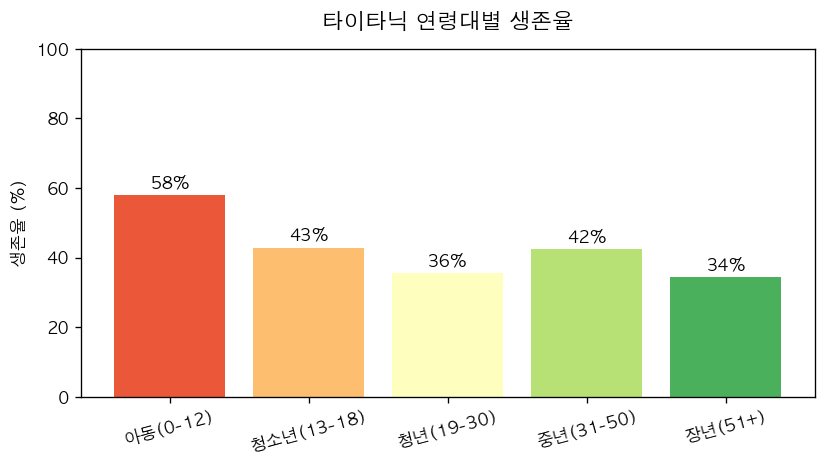
여성 1등석 96.8% vs 남성 3등석 13.5% — 약 7배 격차입니다. “여성과 어린이 먼저”라는 구조가 데이터에 그대로 찍혀 나옵니다. 연령대로 한 번 더 쪼개면 아동의 생존율이 가장 높습니다.
💡 실제 활용 시나리오:
이 교차분석을 매번 손으로 하면 30분, 루프에 “범주형 변수 2개씩 조합해 생존율 교차표와 히트맵을 생성하고, 격차가 큰 조합을 보고하라”는 지시를 한 번 걸면 수십 초에 끝납니다. 사람이 할 일은 “여성 1등석 vs 남성 3등석 7배”라는 해석뿐입니다.
EDA는 원래 반복 작업이에요. 가설 세우고, 자르고, 보고, 다시 자르고. 그래서 루프 설계와 궁합이 가장 좋습니다. 단, “EDA 해줘”는 최악의 프롬프트예요. 탐색의 품질 기준을 rubric으로 걸어야 합니다.

1) Sex × Pclass 생존율 교차분석 루프
목표: 생존(Survived)에 영향을 주는 요인 규명
Rubric:
1. Sex × Pclass 교차표의 생존율을 기준선으로 먼저 제시
2. 발견한 패턴마다 '가설 → 검증 쿼리 → 결론' 3단 기록
3. 통계적으로 무의미한 패턴(표본 30 미만 셀)은 결론에서 제외
4. 최소 5개 가설을 검증하고, 기각된 가설도 기록
종료조건: verifier가 '근거 수치 없는 주장 0건'을 확인하면 종료이렇게 하면 “여성 생존율 74%, 남성 19%” 같은 뻔한 결과에서 멈추지 않고, 1등석 여성은 97% 생존인데 3등석 여성은 50%처럼 교차 패턴까지 파고드는 탐색이 나옵니다. 기각된 가설까지 기록하게 한 게 포인트예요. 다음 섹션의 메모리와 연결되거든요.
💡 실제 활용 시나리오 예시:
이커머스 이탈 분석에서 “가설 5개 이상, 근거 수치 필수, 표본 부족 셀 제외” rubric을 적용하면, 사람이 놓치기 쉬운 ‘신규 가입 + 모바일 결제’ 같은 교차 세그먼트의 이탈 패턴을 에이전트가 먼저 찾아오는 경우가 많습니다.
5. 타이타닉 루프 ③: 모델 개선 hillclimb 루프와 종료조건
마지막은 Parameter Golf의 축소판이에요. 피처 엔지니어링 → 학습 → 평가 → 개선이 반복되는 hillclimb 루프를 타이타닉 생존 예측에 그대로 적용합니다.
1) 의사코드로 보는 hillclimb 구조
best_score = baseline(LogisticRegression, 기본 피처)
while not rubric_satisfied:
실험 = 다음_실험_결정() # 구조적 변경 vs 스칼라 조정
모델 = 학습(실험)
score = 평가(모델, cv=5) # 교차검증 고정
기록(실험, score, 배운점)
if score > best_score: best_score = score
Rubric(verifier가 확인):
- 실험 최소 10회, 그중 구조적 변경(파생변수 추가 등) 3회 이상
- 5-fold CV 정확도 0.82 이상 또는 개선 정체 5회 연속
- 모든 실험의 점수·배운 점이 로그로 남아 있을 것주목할 점은 종료조건을 이중으로 건 것입니다. “목표 달성(0.82)” 또는 “개선 정체 5회”요. 원문에서 Outcomes grader가 모든 기준 충족을 확인한 뒤에야 작업 종료를 허용했던 것처럼, 무한 루프와 조기 포기를 동시에 막는 안전장치예요. Fable 5가 Parameter Golf에서 보여준 “구조적 변경에 베팅하는 회복력”이 타이타닉에서는 FamilySize, Title(호칭) 추출 같은 파생변수 실험으로 나타납니다 🙂
💡 실제 활용 시나리오 예시:
수요 예측 모델 고도화에서 이 이중 종료조건 루프를 밤새 돌려두면, 아침에 “실험 14회, 구조 변경 4회, MAPE 12.3% → 9.8%” 같은 실험 로그와 함께 최적 모델이 준비되어 있는 워크플로가 가능합니다.
6. Memory: 세션을 넘어 똑똑해지는 outer loop
자가 수정 루프가 한 세션 안의 inner loop라면, memory는 세션을 가로지르는 outer loop입니다. 오늘 타이타닉 분석에서 배운 “Age는 그룹별 중앙값이 낫더라”를 다음 주 다른 데이터셋 분석에서 재사용하는 거죠. 원문은 Continual Learning Bench 1.0이라는 벤치마크로 이걸 측정했는데, SQL 데이터베이스에 순차적으로 질문하며 각 질문을 별도 세션으로 처리하는 과제였어요.
① fail → investigate → verify → distill → consult, 5단계의 격차
효과적인 메모리 활용은 실패 기록(fail) → 원인 조사(investigate) → 검증된 사실화(verify) → 일반 규칙화(distill) → 규칙 참조(consult)로 진행되는데, 모델별 도달 단계가 확연히 갈렸습니다.
| 모델 | 도달 단계 | 특징 |
|---|---|---|
| Sonnet 4.6 | 1단계 (fail) | 실패 노트와 미해결 추측만 쌓고 이전 노트를 거의 참조 안 함 |
| Opus 4.7 | 3단계 (verify) | 불확실성 표시한 스키마 참조 생성, 검증 커버리지 7~33% (중앙값 약 17%) |
| Fable 5 | 5단계 완주 | 검증 커버리지 최대 73% (30개 중 22개), 배운 것을 일반 규칙으로 distill |
저도 비슷한 경험이 있는데, 에이전트에게 분석 노트를 남기게 해도 “기록만 하고 안 읽는” 경우가 대부분이었거든요. Fable 5는 기록을 검증된 규칙으로 정제해 다음 과제에서 꺼내 쓴다는 점에서 단계가 다릅니다. 이전에 정리한 Claude Fable 5 완벽 정리에서 다룬 장시간 작업 능력이 메모리와 만나면 진가가 나오는 셈이에요.
💡 실제 활용 시나리오 예시:
사내 DB를 다루는 분석 에이전트에 공유 메모리 파일을 마운트해두면, “amount 컬럼은 센트 단위(검증 완료)” 같은 규칙이 누적되어 새 분석 세션의 시행착오가 매주 눈에 띄게 줄어듭니다.
7. 이런 분들께 적극 추천합니다
- AI에게 분석을 시킬 때마다 단계별로 일일이 지시하느라 지친 데이터 분석가
- 피처 엔지니어링·하이퍼파라미터 실험 사이클을 자동화하고 싶은 데이터 사이언티스트
- 매주 반복되는 데이터 정합성 점검·리포트 검수를 위임하고 싶은 BI/리포팅 담당자
- 에이전트가 “대충 한 번 하고 끝”내는 문제로 고민 중인 AI 자동화 빌더
- Fable 5를 도입했지만 Opus 시절과 같은 방식으로 쓰고 있는 팀 리드·ML 엔지니어
- 타이타닉 같은 익숙한 데이터로 에이전트 워크플로를 처음 실험해보려는 입문자
8. 자주 묻는 질문 (FAQ)
Q. CMA나 8xH100 같은 인프라가 없으면 루프 설계를 못 쓰나요?
A. 아니요, 핵심은 인프라가 아니라 설계 원칙이에요. ① 체크 가능한 rubric을 프롬프트에 명시하고, ② 검증 단계를 분리하고, ③ 이중 종료조건을 거는 것은 Claude Code의 /goal이나 일반 채팅에서도 바로 적용할 수 있습니다. 타이타닉 데이터셋이면 노트북 한 대로 충분해요.
Q. 루프를 돌리면 토큰 비용이 폭증하지 않나요?
A. 늘어나는 건 사실이지만, 통제 장치가 있으면 오히려 효율적입니다. “실험 최소 10회·정체 5회 시 종료”처럼 상한을 rubric에 포함하면 무한 루프를 막을 수 있고, 사람이 단계마다 개입하며 재지시하는 왕복 비용과 비교하면 총 소요는 줄어드는 경우가 많아요.
Q. verifier sub-agent는 어떻게 만드나요?
A. 거창할 필요 없습니다. 가장 쉬운 방법은 작업 완료 후 “새 대화(독립 컨텍스트)”에서 결과물과 rubric만 주고 채점시키는 것이고, Claude Code라면 서브에이전트로 검증 전담 역할을 분리하면 됩니다. 자기가 만든 결과를 자기가 채점하지 않게 하는 것, 그 원칙 하나가 핵심이에요.
✍️ 글을 마치며
Fable 5 시대의 분석 자동화는 “좋은 프롬프트 쓰기”에서 “좋은 루프 설계하기”로 무게중심이 옮겨가고 있습니다. 명확한 rubric, 독립된 verifier, 이중 종료조건, 그리고 세션을 잇는 메모리 — 이 네 가지가 6배의 격차를 만든 재료였어요.
저는 타이타닉 데이터셋으로 3번 섹션의 결측치 점검 루프부터 가장 먼저 해볼 것 같아요. 가장 작고 안전한 과제라서 rubric 작성 감각을 익히기에 딱 좋거든요.
여러분은 어떤 부분이 가장 인상적이셨나요? 댓글로 자유롭게 의견 남겨주세요! 😊